3 min to read
Types of Clustering
A survey of types of clustering

Types of Clustering
Introduction
Clustering (군집화, 클러스터링) 은 주어진 데이터들의 특성을 고려해 데이터 집단(Cluster)을 정의하고 데이터 집단의 대표할 수 있는 대표점을 찾는 비지도 학습 (unsupervised learning) 기법이다.
Types of Clustering
Hierarchical Clustering (계층적 군집화)
Agglomerative (응집형)
AGNES (AGglomerative Nesting) : bottom-up
Divisive (분리형)
DIANA (Divisive ANALysis) : top-down
Partition-based Clustering (분할적 군집화)
distance와 같은 특정 기준에 따라 partition 구성 및 평가
e.g., k-means, k-medoids, etc
Distribution-based (분포 기반)
probability distribution 기반한 통계적 방법
e.g., EM (Expectation-Maximization), etc
Density-based (밀도 기반)
connectivity 와 density functions에 기반
e.g., DBSCAN, OPTICS, etc
Hierarchical Clustering
data set을 관련 정도에 따라 클러스터로 묶고, 이들 클러스터들을 더 큰 클러스터로 묶어가는 방법을 통해 계층화시키는 분석 방법
Dendrogram (계통도)
클러스터 간의 관계를 트리형태로 표현
Agglomerative
AGNES : bottom-up
Divisive
DIANA : top-down
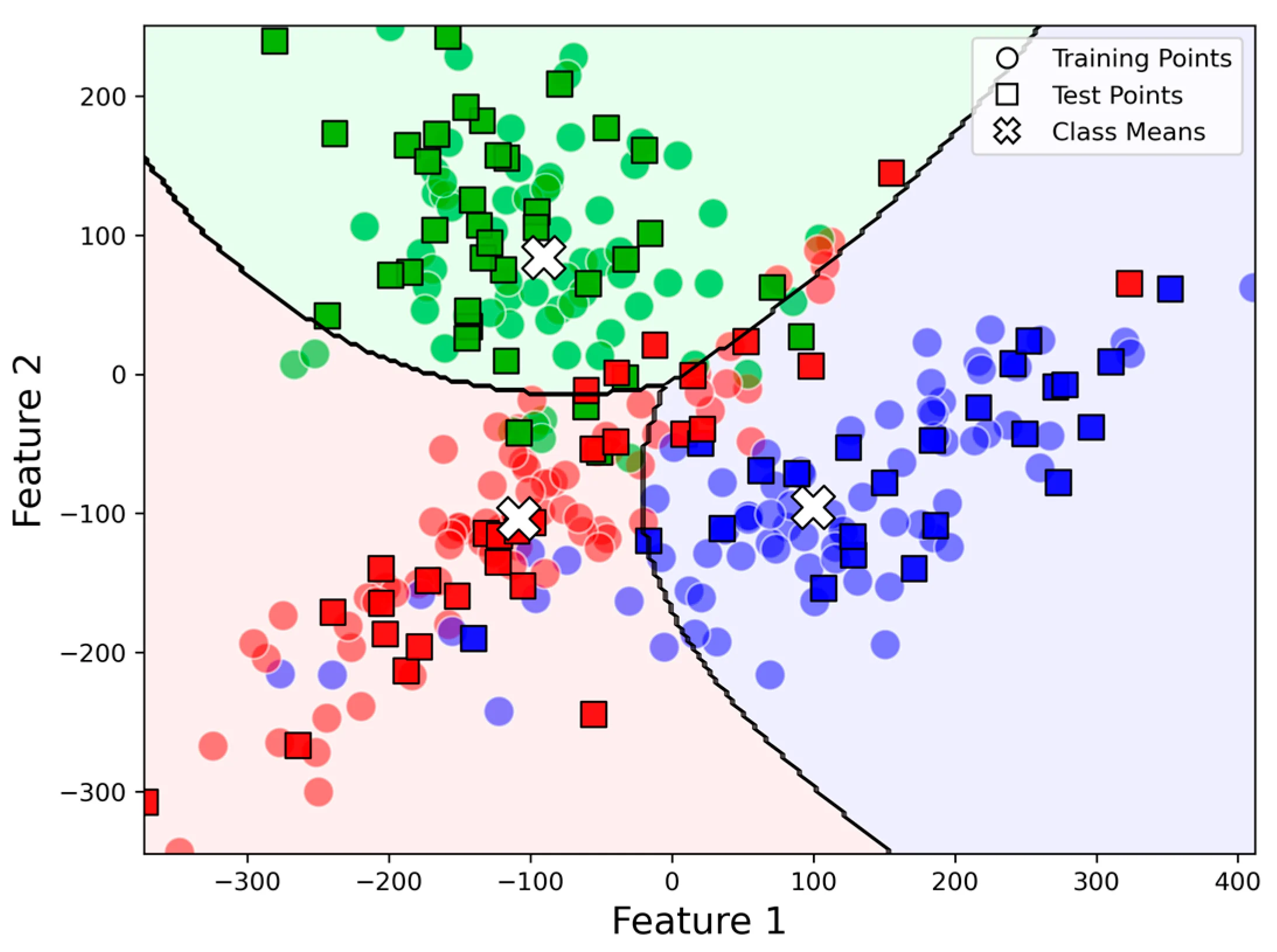
Partitioning-based Clustering
Centroid (클러스터의 중심 or 평균 기반)
K-means 알고리즘
Medoid(빈도수가 많은 중간점 기반)
K-medoids 알고리즘
K-means 알고리즘
원하는 클러스터 개수 K개 만큼 임의의 중심(Centroid) 설정한 후, 각 데이터에 대해 각 중심간의 거리를 계산(Euclidean distance)하고 가장 가까운 centroid의 클러스터에 할당한다. (Expectation-step)
각 클러스터는 평균에 해당하는 새로운 centroid를 선정하고 (Maximization-step) 이전과 동일하면 종료하고, 아닐경우 다시 반복한다.
빠른 속도를 가지고 있지만, 사전 k개의 클러스터를 정해줘야하고 local optimum에 수렴할 수 있다.
또한 Euclidean distance 기반이기 때문에 이상치에 민감하다. 따라서 spherical한 cluster가 아니면 부적절 하다.
K-medoids 알고리즘
K-means와 달리 평균대신 medoid를 사용한다. Euclidean distance 이외의 거리 함수를 사용할 수 있다.
각 클러스터 K개 만큼 중간점을 지정하고, 전체 데이터에 대해 거리를 계산하고 가장 가까운 medoid의 클러스터에 할당한다.
그리고 현재 medoid일때 클러스터내 다른 모든 데이터에 대해 거리를 계산해 반복하면서 최소화 거리를 찾아 medoid로 선정한다
K-means의 이상치에 민감한 약점을 보완하였지만 거리 계산에 시간이 소요된다는 단점이 있다.
Distribution-based Clustering
data 하나가 어떤 cluster에 포함될지 확인할 때 K-means는 거리가 가까운 cluster에 포함시킨다면, 분포기반 클러스터링은 각 분포에 포함될 가능성 (likelihoode)를 계산하여 분포 기반으로 포함 시킨다.
분포는 모수 (모집단의 평균, 분산)가 결정하기 때문에 초기 분포들의 모수들을 임의로 지정하고, 각 분포별로 data의 likelihoode 계산하고 max가 되는 분포로 clustering한다.
data들이 분포에 지정되면, data들로 부터 분포의 모수를 재 계산한다.
쉽게 설명하면, 현재 클러스터(분포)의 모수들에 대해 전체 데이터의 likelihood를 통해 batch한 후, batch된 데이터 기반으로 다시 모수들을 계산한다. 그리고 다시 전체 데이터의 likelihood를 계산해 재배치함으로써 점점 수렴시키는 반복 알고리즘이다.
EM (Expectation Maximization) 알고리즘
분포 기반 클러스터링으로 GMM (Gaussian Mixture Model)에 기반한다.
(GMM assumes that if there are K clusters, the data is generated from a mixture of K Gaussian distibutions)
i.e. maximum likelihood를 갖는 모수(parameter)를 찾는 반복적 알고리즘이다.
EM 알고리즘은 K개의 모델에 대한 각 매개변수 θ를 임의로 지정하고 (Gaussian 분포가 일반적), 이 θ를 이용해, 각 data별로 K개의 분포에 속할 확률(likelihood)을 모두 계산한다. 그리고 data는 likelihoode가 최대가 되는 분포에 속하도록 하게 한다. (soft-assignment 시에는 여러 분포 포함 가능)
각 모델에 속한 data를 기반으로 구한 확률을 이용해서 θ를 재추정하고 수렴시까지 반복한다.
K-means와 EM 둘다 종료시까지 반복하는 반복 알고리즘이지만, K-means는 거리기반이고 EM은 분포기반이라는 큰차이가 존재한다.
Density-based Clustering
밀도기반 군집화는 연결성, 밀도 (동일 면적에 데이터 개수)에 기반한다.
DBSCAN(Density-based spatial clustering of applications with noise)
data가 몰려있어 밀도가 높은 부분을 클러스터로 만드는 방식이다.
점 p로 부터 반경 e(epsilon)안에 데이터가 m(minPts)개 이상이면 군집으로 판별한다.
core point : 한점을 기준으로 반경 e안에 점이 m개 이상일때 (군집 생성)
border point : m개 미만일때 (다른 군집에 포함)
noise point : 어느 군집에도 포함되지 않는 점
군집 내에 다른 군집의 코어점이 있으면 하나의 군집으로 연결한다.
군집의 개수를 미리 정하지 않아도 되고 군집 연결을 통해 기하학적 형태의 군집이 가능하다는 장점이 있다. 또한 군집기반 이상치 탐지 용법으로도 사용된다.
Reference
Pattern Recognition and ML
EM Clustering
Wikipedia documents
Comments