4 min to read
A Survey of Deep Learning for Anomaly Detection
Deep Learning for Anomaly Detection
Deep Learning for Anomaly Detection
Introduction
이상치 탐지(Anomlay Detection)은 데이터의 정상 패턴에서 크게 벗어나는 관측값이나 행동을 식별하는 작업이다.
이러한 이상 현상은 장비 고장, 구조적 결함, 센서 오류 등 현대의 가상 물리 시스템(Cyber-physical system, CPS)에서 안정성과 안전성에 직접적인 영향을 미칠 수 있다.
다양한 산업 분야에서 대규모 데이터가 센서등에 의해 실시간으로 생성됨에 따라, 효과적인 이상치 탐지는 시스템의 신뢰성 확보와 비용 절감, 운영효율 향상을 위한 필수적인 요소가 되었다.
Normality vs Novelty vs Anomalies(Outliers)
Normality 은 시스템이 평소에 보여주는 일반적이고 반복적인 정상패턴이다.
Novelty 는 Normality 데이터와의 본질적인 특성은 같지만, 유형이 다른 관측치이다.
Anomaly 는 대부분의 데이터와 특성이 다른 관측치이다
Test sample에 대한 Output feature가 특정 Class에 해당하는 output feature distribution을 보이는지 확인해야 한다.
Type of Anomalies
이상치의 종류는 크게 3가지로 분류할 수 있다.
Pattern 종류에 따라 분류
Point : 말 그대로의 이상치, 정상과 본질적으로 다른 희소한데이터
Contextural or Conditional : 조건부 이상치, 즉 특정 조건이 충족될 때 이상치로 판단될 수 있다.
Collective or Group : 한 번 이상치가 발생할 때 대규로모 발생한다 (e.g., 디도스 공격)
비교 범위에 따라 분류
Local outlier : 전체 분포에서는 정상처럼 보이지만 이웃 데이터와 비교했을때 이상치인 값 (cluster 구조일때 중요하다, LOF 같은 방법으로 탐지)
Global outlier : 전체 데이터 분포 기준에서 멀리 떨어진 극단값
>
Input data type에 따라 분류
Vector outlier : multi-dimension으로 이루어진 data (numeric/ categorical value)
Graph outlier : 데이터간 상호 의존성을 나타내는 node와 edge로 이루어진 data
Label of Anomalies
Anomaly Detection 모델을 학습하는데 중요한 여부는 label의 여부이다.
각 경우에 따라 올바른 모델을 사용할 필요가 있다.
Supervised Model
정상 데이터와 비정상 데이터에 대한 label이 모두 존재하는 경우 사용한다.
Label 정보로 인한 높은 Detection 성능을 지니며 사실상 Classifiaction 문제와 동일하기 때문에 분류모델을 사용할 수 있어 사용가능한 모델이 많다.
하지만 label 정보가 존재한다는 것은 현실적으로 매우 어려우며, 존재하더라도 양적차이가 날 확률이 높아 class 불균형으로 인한 문제가 발생할 수 있다.
ex) SVM, Logistic Regrassion, Random Forest, etc
Semi-supervised Model
정상 데이터에 대한 label만 존재하는 경우, 정상데이터에 대해 학습시키고 비정상데이터를 이상치로 간주한다.
대부분의 경우 정상데이터와 그에 따른 label을 확보하는 것이 가능하며 가장 현실적인 경우이다. 하지만 정상 데이터만으로 학습하기 때문에 representation feature가 over-fitting 될 확률이 높다. 또한 지도 학습에 비해 모델 성능이 떨어진다.
ex) Autoencoder, SVDD, OCSVM, IForest, etc
Unsupervised Model
전체 데이터가 주어져있고 label 정보가 없을 경우 사용할 수 있다.
모든 경우에도 사용할 수 있는 방법론이지만, 전체 데이터 셋 중 대부분이 정상데이터라는 가정이 필요하며, 가장 성능이 떨어지고 noise에 민감하다.
ex) K-Means distance 기반, LOF, Graph-based Outlier Detection, MCD , etc
Why is Deep Learning needed?
현대 데이터(이미지, 시계열, 언어 등)은 사람이 만든 수식이나 단순 모델로는 구조가 복잡하지만 딥러닝을 이용함으로써 비선형,고차원 구조를 통해 복잡한 패턴을 학습할 수 있다.
전통 ML 기법은 어떤 feature를 추출해야 할지, 전처리가 필요한지 설계해야 하지만 딥러닝은 raw data -> feature -> representation -> output 과정을 end-to-end로 스스로 학습한다.
또한 비지도·반지도 학습과도 결합해 Deep SVDD, VAE, AE + OCSVM 등 전통기법보다 강력한 성능을 보이고 있다.
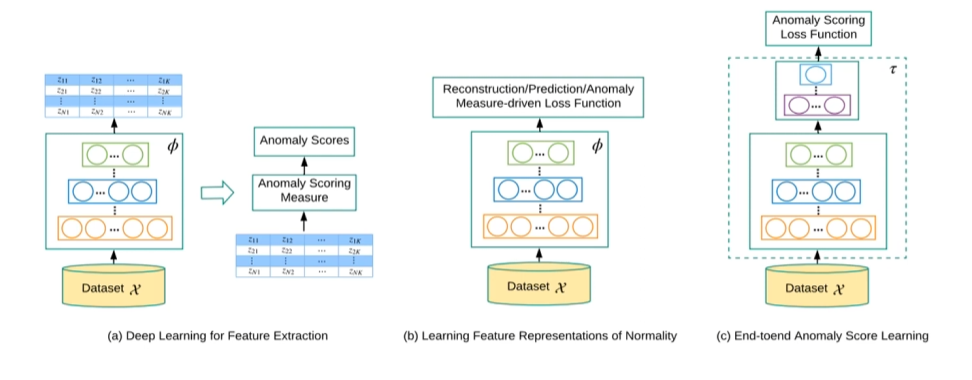
Deep Anomaly Detection approach 분류
Deep Learning for Feature Extraction
Deep Learning을 오직 Feature Extraction 에만 사용하고, acnomaly scoring은 전통적 ML기법(OCSVM, IForest, etc) 로 별도 수행한다.
AlexNet, VGG, ResNet 등의 pre-trained CNN 모델을 통해 Feature Extraction 진행한 후 해당 feature 기반으로 anomaly scoring 진행한다.
Learning Feature Representations of Nomality
모델이 정상 데이터의 분포적 구조를 직접 학습하도록 Reconstruction, Prediction 기반의 loss를 사용하여 nomality를 잘 표현하는 latent representation을 학습하는 방식이다.
학습 후 anomaly score는 보통 reconstruction error, prediction error 등의 기준으로 계산된다.
End-to-End Anomaly Score Learning
Anomaly score 자체를 loss function으로 직접 최적화 하여 feature extraction과 anomaly scoring을 하나의 end-to-end 구조로 동시에 학습하도록 하는 방식이다.
대표적으로 Deep SVDD, OCNN 등이 있다.
Categorization of Deep Anomaly Detection
Reference
R. Chalapathy and S. Chawla, “Deep learning for anomaly detection: A survey,” arXiv preprint arXiv:1901.03407, 2019.
K. Choi, J. Yi, C. Park, and S. Yoon, “Deep Learning for Anomaly Detection in Time-Series Data: Review, Analysis, and Guidelines,” IEEE Access, vol. 9, pp. 120043-120065, 2021, doi:10.1109/ACCESS.2021.3107975
A. Garg, W. Zhang, J. Samaran, S. Ramasamy, and C.-S. Foo, “An Evaluation of Anomaly Detection and Diagnosis in Multivariate Time Series,” arXiv preprint arXiv:2109.11428, 2021
Comments