3 min to read
Naïve Bayes Classification
Stochastic Modeling of Naïve Bayes Classification
Naïve Bayes Classification
Introduction
Naïve Bayes Classification는 Bayes’ Theorem을 기반으로한 확률적 분류 알고리즘이다.
Naïve (순진한)의 의미는 입력 feature들이 서로 독립(independent)임을 가정하기 때문인데, 물론 현실 데이터는 독립이 아닌 경우도 많지만, 이러한 가정 덕분에 계산이 단순해지고 빠르다는 장점이 있다.
Classification
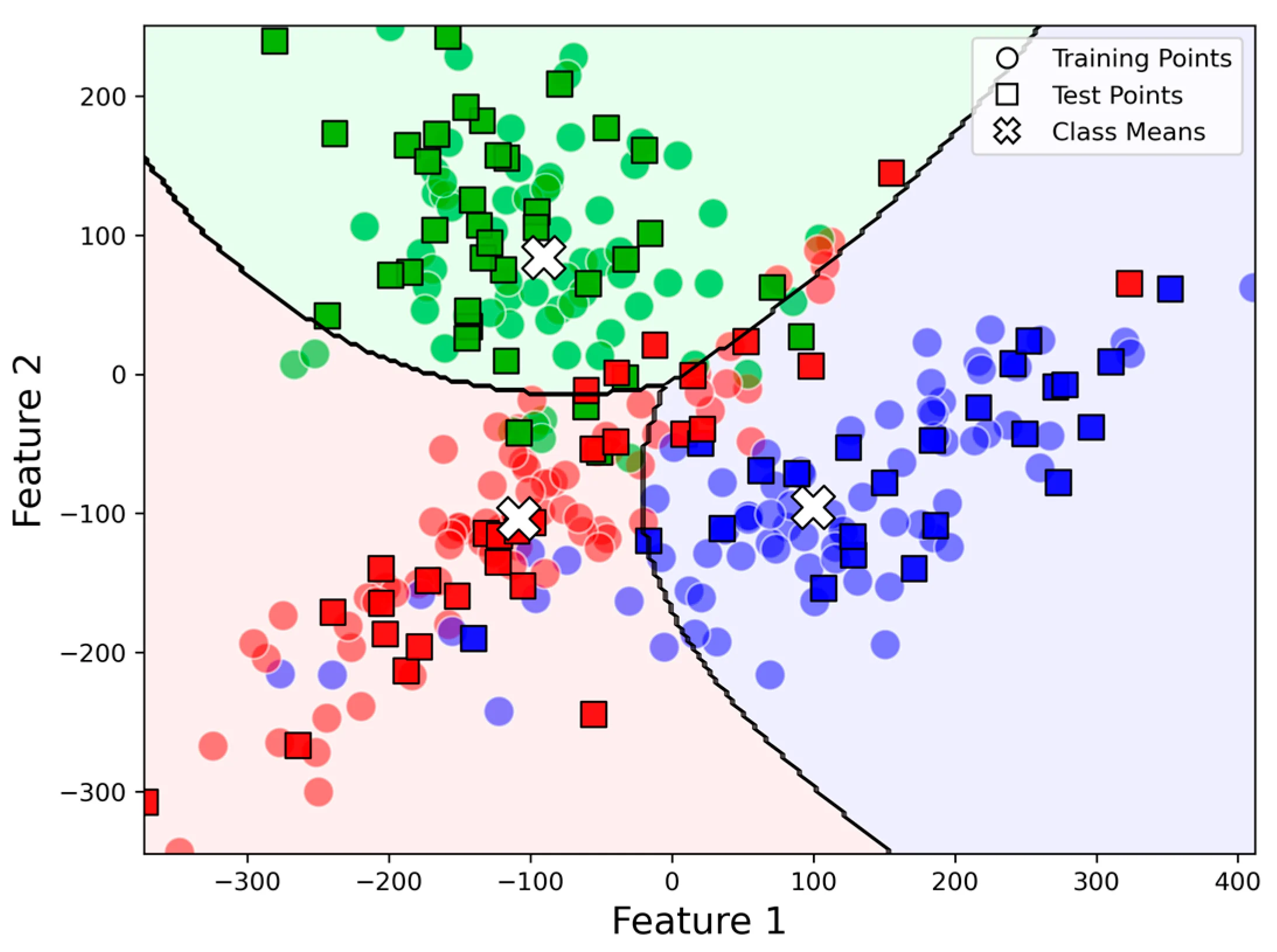
Classification은 주어진 class 중 data가 어디에 속하는지 탐색하는 방법이다.
cf. Clustering : 정해 놓은 class 없이 묶는다 (K-means : 개수 K만 지정한다).
따라서 이는 지도학습 (Supervised Learning)에 속하며 보통 다음과 같은 구성으로 되어있다.
Training Data set : Class가 주어진 Labeled dataset
Feature Extraction : 특징 추출 (다양한 method가 존재한다 대표적으로 Autoencoder, PCA 등이 있다)
Classifier : 분류 algorithm을 지정해서 학습을 한 후 Class를 지정해 준다.
대표적인 Classification Algorithm으로는 Regression, Logistic Regrassion, Naive Bayes, kNN 등이 있다.
Naïve Bayes Classification
나이브 베이즈 분류 알고리즘은 Bayes’ Theorem (조건부 확률)을 이용하는 확률 분류기 이다. 데이터의 feature들은 서로 독립성을 가정하여 계산량을 감소시킨다.
Bayes’ theorem
\[Pr(A|B) = \frac{Pr(B|A)Pr(A)}{Pr(B)}\]· Pr(A) : A의 prior(사전확률)
· Pr(A|B) : B가 주어졌을때 A의 posterior(사후확률)
· Pr(B|A) : A가 주어졌을때 B의 조건부 확률 (likelihood)
· Pr(B) : B의 evidence(관측치)이며 정규화 상수 역할, Pr(B|A)를 A에 대해 적분함으로 써 계산 가능하다 (Total Probability Theorem)
Stochastic Modeling
데이터들은 n개의 feature : vector x = (x_1, …., x_n)
k개의 Class (C_1, …., C_k)로 분류할때 p(C_k|x_1, …., x_n)이 최대가 되는 Class에 분류한다.
이를 식으로 적으면 다음과 같이 쓸 수 있다
\[p(C_{k}|x) = \frac{p(C_{k})p(x|C_{k})}{p(x)}\]확률 용어로 쓰면 다음과 같이 쓸 수 있다
\[posterior = \frac{prior \times likelihood}{evidence}\]여기서 분모는 상수여서 의미없기 때문에 다음 결합 확률로 모델링 할 수 있다.
\[p(C_{k},x_1,...,x_{n}) = p(C_{k})p(x|C_{k})\]이를 연쇄법칙으로 다시 정리하면 다음과 같다
\[p(C_k, x_1, \ldots, x_n) = p(C_k)\, p(\mathbf{x} \mid C_k)\] \[= p(C_k)\, p(x_1, \ldots, x_n \mid C_k)\] \[= p(C_k)\, p(x_1 \mid C_k)\, p(x_2, \ldots, x_n \mid C_k, x_1)\] \[= p(C_k)\, p(x_1 \mid C_k)\, p(x_2 \mid C_k, x_1)\, p(x_3, \ldots, x_n \mid C_k, x_1, x_2)\] \[= p(C_k)\, p(x_1 \mid C_k)\, p(x_2 \mid C_k, x_1)\, \cdots\, p(x_n \mid C_k, x_1, x_2, x_3, \ldots, x_{n-1})\]나이브 베이즈의 독립성 가정에 따라 \(if \ i \neq j , \ p(x_i|C_k,x_j) = p(x_i|C_k),\)
\[p(x_i|C_k,x_j,x_k) = p(x_i|C_k),\] \[p(x_i|C_k,x_j,x_k, x_l) = p(x_i|C_k),\]따라서 조건부 확률식에서 분모가 상수라면
\[p(C_k|x_1,...,x_n) \propto p(C_k,x_1,...,x_n)\] \[\propto p(C_k)p(x_1|C_k)p(x_2|C_k) ...\] \[\propto p(C_k)\prod_{i=1}^{n} p(x_i|C_k)\]이를 통해 Classifier를 생성하면 각 클래스 C_1,… 등에 대해 posterior (또는 분자만) 계산하여, 확률값이 최대가 되는 C_k에 분류하면 된다
\[\hat{y} = \underset{k \in \{1,...,k\}}{argmax}p(C_k)\prod_{i=1}^{n}p(x_i|C_k)\]i.e. 입력값 x에 대한 C의 사후확률이 최대가 되는 C_k 클래스에 분류한다 (argmax 사전 x 우도함수)
Distribution
데이터들의 특성이 어떤 분포를 따른다고 가정하느냐에 따라 다른 모델이 된다
Gaussian distribution
연속적인 feature일때 주로 사용한다
Training dataset으로 각 클래스별/ 특성별로 분포를 결정하고 (class C일때, 평균 μ, 분산 σ^2),
예측 data가 주어지면, 특성 별로 우도함수를 계산한다.
\[p(x=v|c) = \frac{1}{\sqrt{2\pi\sigma^2_c}}exp({-\frac{(\nu-\mu_c)^2}{2\sigma_c^2}})\]그 외에 이산적인 특성일때 (있다/ 없다)는 다항분포나 베르누이를 사용한다.
Example (by Wikipedia)
다음 측정된 feature (height, weight, footsize)를 보고 남, 녀 class 분류해보자.
Training dataset
연속적인 feature이므로, Gaussian distribution을 가정할때, 생성된 classifier
여기서 prior는 0.5로 가정한다 (실제 인구 분포나 훈련 dataset내의 빈도를 기반으로 결정할 수도 있다)
분포가 결정 되었으므로 likelihood도 계산할 수 있다.
Test
height = 6(feet), wight = 130(lbs), footsize = 8(inches) 일때 성별을 예측해보자.
남성이 posterior와 여성의 posterior를 비교해 큰 값을 선택하여 예측하면 된다.
남성
\[p(male) = 0.5\] \[p(height|male) = \frac{1}{\sqrt{2\pi\sigma^2}}exp(\frac{-(6-\mu)^2}{2\sigma^2}) \approx 1.5789\] \[p(weight|male) = 5.9981 · 10^{-6}\] \[p(foot size|male) = 1.3112·10^{-3}\] \[posterior \ numerator (male) = thier \ product = 6.1984·10^{-9}\]여성
\[P(female) = 0.5\] \[p(height|female) = 2.23445·10^{-1}\] \[p(weight|female) = 1.6789·10^{-2}\] \[p(foot size|female) = 2.8669·10^{-1}\] \[posterior \ numerator (female) = their \ product = 5.3778·10^{-4}\]여성의 사후 확률이 더 크므로 여성으로 예측
Comments